Home > docs > processes v2 > Migration from v1
Migration from v1
Overview
Starting from version 1.57.0, Concord introduces a new runtime for process execution.
The new runtime features require changes in flows and plugins. That’s why initially it will be an opt-in feature - both v1 and v2 versions will coexist for foreseeable future.
To enable the v2 runtime, add the following to your concord.yml file:
configuration:
runtime: "concord-v2"
Alternatively, it is possible to specify the runtime directly in the API request:
$ curl ... -F runtime=concord-v2 http://concord.example.com/api/v1/process
Check out below for new and updated features of v2.
New Directory Structure
The v1 runtime supports loading additional files from the
${workDir}/concord/*.yml directory. Any YAML file in the concord directory
treated as a Concord YAML file. Sometimes it might get in the way,
especially when imports are used – the
${workDir}/concord directory is the default target for imports and
you might end up with other YAML files imported into the directory.
The v2 runtime requires Concord YAML files in the concord directory to have
a special .concord.yml extension, for example:
# the main file
/concord.yml
# additional files
/concord/my.concord.yml
/concord/extra.concord.yml
# not a Concord file, won't be loaded
/concord/values.yaml
See more details in the Directory structure documentation.
New SDK
Tasks that wish to use all features provided by the v2 runtime must use the new SDK module:
<dependency>
<groupId>com.walmartlabs.concord.runtime.v2</groupId>
<artifactId>concord-runtime-sdk-v2</artifactId>
<version>2.35.0</version>
<scope>provided</scope>
</dependency>
Notable differences:
invariables passed as aVariablesobject. Additionally, all task inputs must be explicit: taskinparameters and flow variables are now separate;- tasks can now return a single
Serializablevalue; Contextcan now be@Inject-ed.
Task classes can implement both the new com.walmartlabs.concord.runtime.v2.sdk.Task
and the old com.walmartlabs.concord.sdk.Task interfaces simultaneously, but
it is recommended to keep the common logic separate and create two classes
each implementing a single Task interface:
// common logic, abstracted away from the differences between v1 and v2
class MyTaskCommon {
TaskResult doTheThing(Map<String, Object> input) {
return "I did the thing!";
}
}
// v1 version of the task
@Named("myTask")
class MyTaskV1 implements com.walmartlabs.concord.sdk.Task {
void execute(Context ctx) {
Map<String, Object> result = new MyTaskCommon()
.doTheThing(ctx.toMap())
.toMap();
// result is saved as a flow variable
ctx.setVariable("result", result);
}
}
// v2 version of the task
@Named("myTask")
class MyTaskV2 implements com.walmartlabs.concord.runtime.v2.sdk.Task {
Serializable execute(Variables input) {
// return the value instead of setting a flow variable
return new MyTaskCommon().doTheThing(input.toMap());
}
}
More details in the Tasks v2 documentation.
Variable Scoping Rules
In the v1 runtime all flow variables are global variables:
configuration:
runtime: concord-v1
flows:
default:
- set:
x: 123
- log: "${x}" # prints out "123"
- call: anotherFlow
- log: "${x}" # prints out "234"
anotherFlow:
- log: "${x}" # prints out "123"
- set:
x: 234
In addition, task inputs are implicit:
configuration:
runtime: concord-v1
flows:
default:
- set:
url: https://google.com
- task: http
in:
method: "GET" # 'url' is passed implicitly
There is no difference in v1 between task inputs and regular variables. From
the task’s perspective values in the in block, variables defined in the flow
prior to the task’s call and process arguments are the same thing.
This could sometimes lead to hard-to-debug issues when one part of the flow reuses a variable with the same name as one of the task’s inputs.
In v2 we changed the rules for variable scoping. Let’s take a look at the same example, but running in v2:
configuration:
runtime: concord-v2
flows:
default:
- set:
x: 123
- log: "${x}" # prints out "123"
- call: anotherFlow
- log: "${x}" # prints out "123"
anotherFlow:
- log: "${x}" # prints out "123"
- set:
x: 234
In v2 variables set in a flow visible only in the same flow or in flows
called from the current one. To “get” a flow variable “back” into the callee’s
flow you need to use the out syntax:
configuration:
runtime: concord-v2
flows:
default:
- call: anotherFlow
out: x
- log: "${x}"
anotherFlow:
- set:
x: 123
Task inputs are now explicit – all required parameters must be specified in
the in block:
configuration:
runtime: concord-v2
flows:
default:
- set:
url: https://google.com
- task: http
in:
url: "${url}" # ok!
method: "GET"
- task: http
in:
method: "GET" # error: 'url' is required
Scripting
In v1 the Context object injected into scripts provides methods to get and set
flow variables.
configuration:
runtime: concord-v1
flows:
default:
- script: groovy
body: |
// get a variable
def v = execution.getVariable('myVar')
// set a variable
execution.setVariable('newVar', 'hello')
In v2, the injected Context object has a variables() method which returns a
Variables object. This object includes a number of methods for interacting with flow variables.
configuration:
runtime: concord-v2
flows:
default:
- script: groovy
body: |
// get a variable
def v = execution.variables().get('myVar')
// get a String, or default value
String s = execution.variables().getString("aString", "default value")
// get a required integer
int n = execution.variables().assertInt('myInt')
// set a variable
execution.variables().set('newVar', 'Hello, world!')
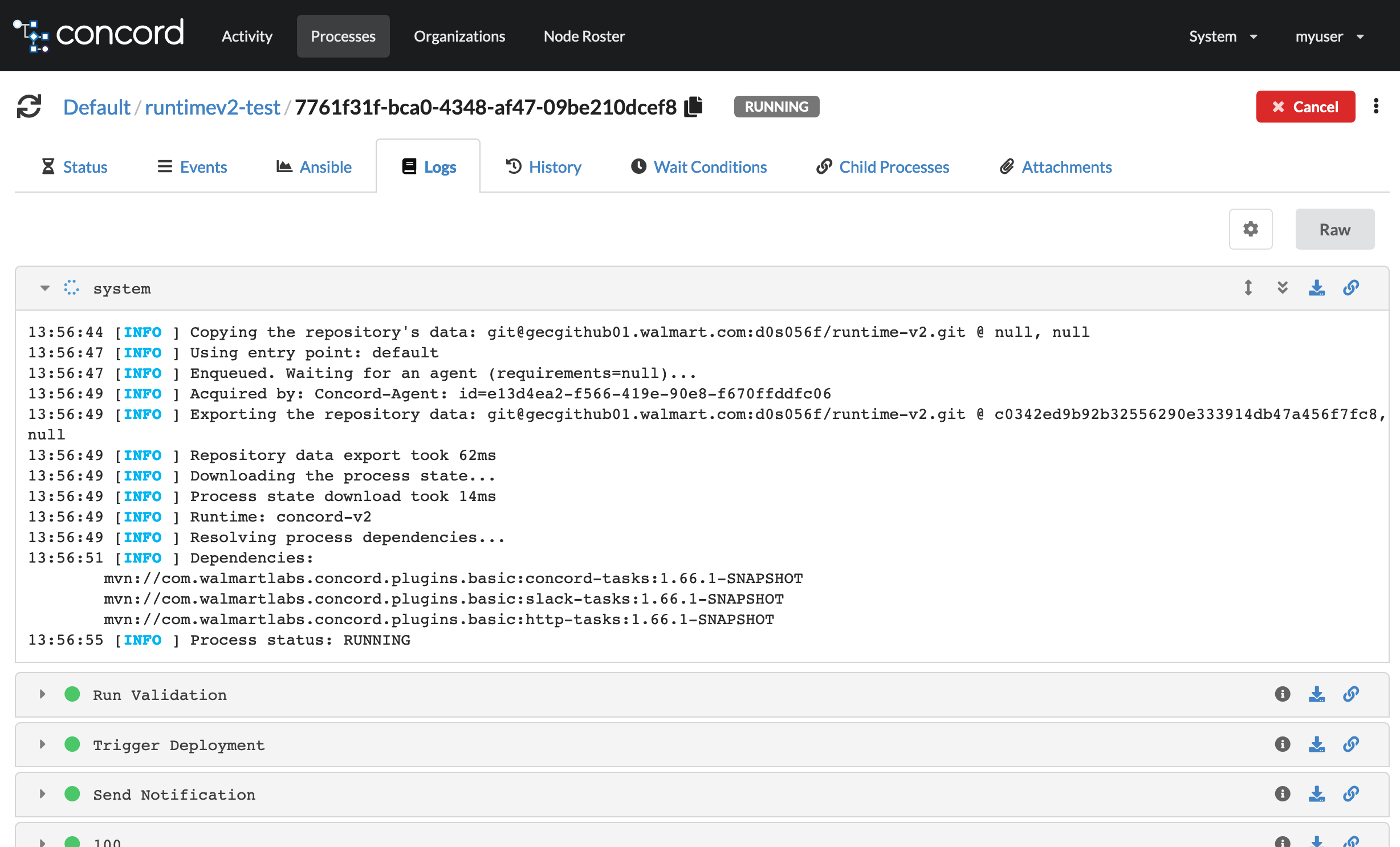
Segmented Logging
In v1 the process log is a single steam of text - every task and log
statement writes their output into a single log file. In v2 most of the flow
elements get their own log “segment” – a separate log “file”:
This feature is enabled by default and should work “out of the box” for
most plugins that use org.slf4j.Logger for logging.
The runtime also redirects Java’s System.out and System.err into
appropriate log segments. For example, if you use puts in
JRuby or println in
Groovy, you should see those lines
in correct segments.
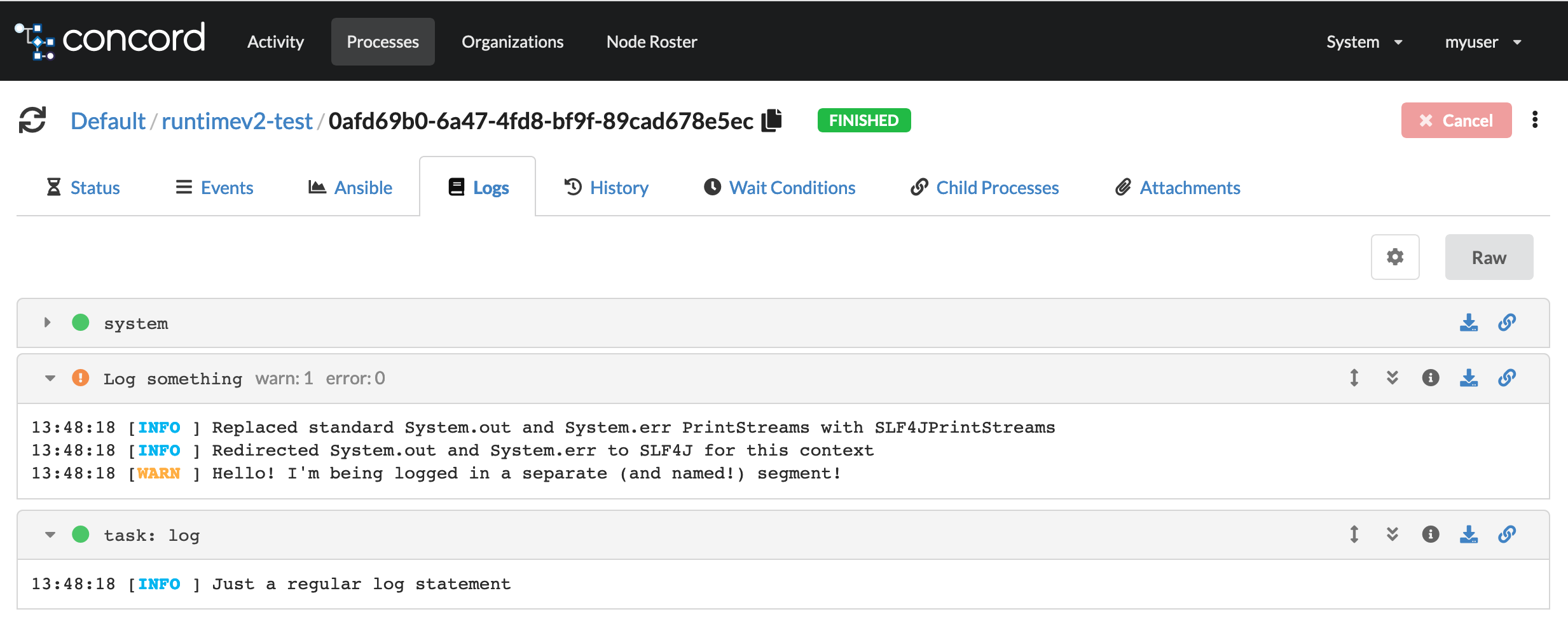
Segments can be named:
flows:
default:
- name: Log something
task: log
in:
msg: "Hello! I'm being logged in a separate (and named!) segment!"
level: "WARN"
- log: "Just a regular log statement"
Should produce a log looking like this:
The name field also supports expressions:
flows:
default:
- name: Processing '${item}'
task: log
in:
msg: "We got: ${item}"
loop:
items:
- "red"
- "green"
- "blue"
Currently, the following steps can use name:
taskcallexprlogthrowscript
If name is not specified, the runtime pick a default value, e.g.
task: <...> for task calls.
The toolbar on the segments allows various actions to be performed on the logs. Users can expand the segment, auto scroll to the end, see YAML info, download the log segment as a file and generate a unique URL for the segment to facilitate ease of sharing logs.
Parallel Execution
The v1 runtime provides no satisfactory ways to run flow steps in parallel
in one single process. For parallel deployments it is possible to use Ansible
and its forks feature. There’s also
a way to “fork” a process, i.e. to run a flow
in another process while inheriting current flow variables.
The v2 runtime was designed with parallel execution in mind. It adds a new
step - parallel:
flows:
default:
- parallel:
- task: http
in:
url: https://google.com/
out: googleResponse
- task: http
in:
url: https://bing.com/
out: bingResponse
- log: |
Google: ${googleResponse.statusCode}
Bing: ${bingResponse.statusCode}
Check the documentation for the parallel step
for more details.
Better Syntax Errors
There are multiple improvements in v2 in the Concord DSL syntax validation and error reporting.
Let’s take this simple YAML file as an example:
flows:
- default:
- log: "Hello!"
The flows block should be a YAML object, but in this example it is a list.
Here’s how v1 reports the error (minus the stack traces):
Error while loading the project, check the syntax. (concord.yml): Error @ [Source: (File); line: 2, column: 3].
Cannot deserialize instance of `java.util.LinkedHashMap<java.lang.Object,java.lang.Object>` out of START_ARRAY token
For comparison, here’s how v2 reports the same error:
Error while loading the project, check the syntax. (concord.yml): Error @ line: 2, col: 3. Invalid value type, expected: FLOWS, got: ARRAY
while processing steps:
'flows' @ line: 1, col: 1
Another example:
flows:
default:
- if: "${true}"
then:
log: "It's true!"
In this example the then block should’ve been a list.
Here’s how v1 reports the error:
Error while loading the project, check the syntax. (concord.yml): Error @ [Source: (File); line: 6, column: 1].
Expected: Process definition step (complex).
Got [Atom{location=[Source: (File); line: 3, column: 7], token=START_OBJECT, name='null', value=null}, Atom{location=[Source: (File); line: 3, column: 7], token=FIELD_NAME, name='if', value=null}, Atom{location=[Source: (File); line: 3, column: 11], token=VALUE_STRING, name='if', value=${true}}, Atom{location=[Source: (File); line: 4, column: 7], token=FIELD_NAME, name='then', value=null}, Atom{location=[Source: (File); line: 5, column: 9], token=START_OBJECT, name='then', value=null}, Atom{location=[Source: (File); line: 5, column: 9], token=FIELD_NAME, name='log', value=null}, Atom{location=[Source: (File); line: 5, column: 14], token=VALUE_STRING, name='log', value=It's true!}, Atom{location=[Source: (File); line: 6, column: 1], token=END_OBJECT, name='then', value=null}, Atom{location=[Source: (File); line: 6, column: 1], token=END_OBJECT, name='null', value=null}]
The same YAML in v2:
Error while loading the project, check the syntax. (concord.yml): Error @ line: 5, col: 9. Invalid value type, expected: ARRAY_OF_STEP, got: OBJECT
while processing steps:
'then' @ line: 4, col: 7
'if' @ line: 3, col: 7
'default' @ line: 2, col: 3
'flows' @ line: 1, col: 1
Not only it makes more sense for users unfamiliar with the internals of the Concord DSL parsing, but it also shows the path to the problematic element.
Future versions will further improve the parser and the parsing error reporting.
Better Flow Errors
In Concord flows all exceptions are typically handled in error blocks. To
reference the last raised exception one can use the ${lastError} variable.
In v1, Concord wraps all exceptions into an internal error type - BpmnError.
To get the original exception object users required to use ${lastError.cause}
expression.
In v2 all ${lastError} values are the original exceptions thrown by tasks or
expressions. Those values can still be wrapped into multiple exception types,
but Concord no longer adds its own.
For example:
flows:
default:
- try:
- log: "${invalid expression}"
error:
- log: "${lastError}"
This is how it looks when executed in v1:
10:23:31 [INFO ] c.w.concord.plugins.log.LogUtils - io.takari.bpm.api.BpmnError: Error at default/e_0: __default_error_ref
The exception message doesn’t contain any useful information. It is being
hidden in the lastError.cause object. If we try to log lastError.cause, we
get a slightly better result:
10:26:46 [INFO ] c.w.concord.plugins.log.LogUtils - javax.el.ELException: Error Parsing: ${invalid expression}
Here’s the v2 output:
10:24:46 [ERROR] (concord.yml): Error @ line: 4, col: 11. Error Parsing: ${invalid expression}
10:24:46 [INFO ] {}
com.sun.el.parser.ParseException: Encountered "expression" at line 1, column 11.
Was expecting one of:
"}" ...
"." ...
"[" ...
...skipped...
"+=" ...
"=" ...
Not only it contains the line and column numbers where the exception (approximately) occurred, it is also more detailed and contains the original error.
Run Flows Locally
The v2 runtime significantly simplifies embedding - the runtime itself can be used as a regular Java library.
The updated Concord CLI tool is leveraging this ability to provide a way to run Concord flows locally, without the need for a Concord cluster instance:
# concord.yml
flows:
default:
- log: "Hello!"
$ concord run
Starting...
16:41:34.894 [main] Hello!
...done!
Most of the regular features are supported: secrets, decryptString, external
dependencies, etc.
For more details, check the updated Concord CLI documentation.
